

Data drives underwriting, transformation and risk assessment. As such, the life insurance industry is constantly working to identify new sources of information that provide insight into mortality risk. Electronic health records (EHRs) are already helping life underwriters assess risk while supporting a faster and less invasive buying experience for customers.
Medical claims records (MCRs) and codes are one of the newest resources at our disposal; however, there are some challenges to overcome first. In this blog, we’ll talk about our exploratory journey with using MCRs in risk assessment and where we are today.
What are medical claims records?
MCRs contain codes that a healthcare provider submits to insurers for reimbursement. The diagnosis and procedural codes that make up MCRs provide important information about the applicant’s medical conditions and history, all of which impact risk.
The challenges with MCR
Our challenge is extracting as much value as possible from MCRs, but cutting through the noise is not a straightforward task.
the biggest challenge in using MCR as part of an automated underwriting program is managing the volume and complexity
Perhaps the biggest challenge in using MCR as part of an automated underwriting program is managing the volume and complexity. It takes commitment and hefty resources to make sense of MCR’s five classification systems (ICD-11, ICD-10-CM, ICD-10-PCS, CPT and HCPCS Level II) and the volume of codes for each (ICD-10 alone has 68,000 different codes!).
In manual underwriting, it can be prohibitively time-consuming for an underwriter to make sense of medical claims codes within an EHR. Therefore, the first step is to process or translate the codes into useful and, most importantly, actionable information.
Yet another challenge relates to the way codes are created. There are a few studies on this topic, but one states that 80% of all medical bills contain errors1. Additionally, medical facilities often choose codes that are intentionally vague to expedite full reimbursement. They’ve also been known to create a diagnosis code that ensures that a needed test will be fully covered for the patient. Digital tools that leverage MCRs for risk assessment need to consider ways to cross-reference a medical condition with another data source in order to verify a diagnosis.
Data science to the rescue
In our initial experiments with MCRs, we used a robust set of automated rules to identify codes and medical conditions that were considered high-risk. This approach flagged risk in nearly all applicants that had MCRs. As we tried to develop more sophisticated rules, the complexity became overwhelming.
MCR’s potential impact on data-driven risk assessment is too great to be ignored.
With those challenges, why continue to pursue MCR as a potential data source for accelerated underwriting? In a word, opportunity. As data scientists with a passion for solving problems, MCR’s potential impact on data-driven risk assessment is too great to be ignored.
Finally, in 2023, the effort is bearing fruit.
Cracking the MCR code(s)
Because medical claims codes are specific, they provide greater insight into an applicant’s medical conditions. Our newest endeavor, LifeScore PRISMSM (Predictive Risk Impairment Specific Models) takes advantage of this level of detail. It’s a growing suite of models that combines MCRs with other data sources to help predict the presence and severity of diabetes, hypertension and psychiatric disorders. These conditions represent the most common reasons an applicant is kicked out of automated underwriting. Our goal is to keep them in.

MCR helps fine-tune risk assessment
Under the hood of LifeScore PRISM, MCR data interacts with other data sources, such as prescription history and public health data. By detecting the presence and severity of impairments early in the underwriting process, the model provides more information to gauge an applicant’s health and risk.
Like other predictive risk models, LifeScore PRISM uses machine learning to study and identify patterns and correlations between MCRs and other data. While some of those patterns may indicate a poor risk profile, others indicate only a slightly elevated risk. Whereas a severe, complicated diabetic condition may be kicked out, an applicant with a well-managed version of diabetes may still qualify for automated underwriting.
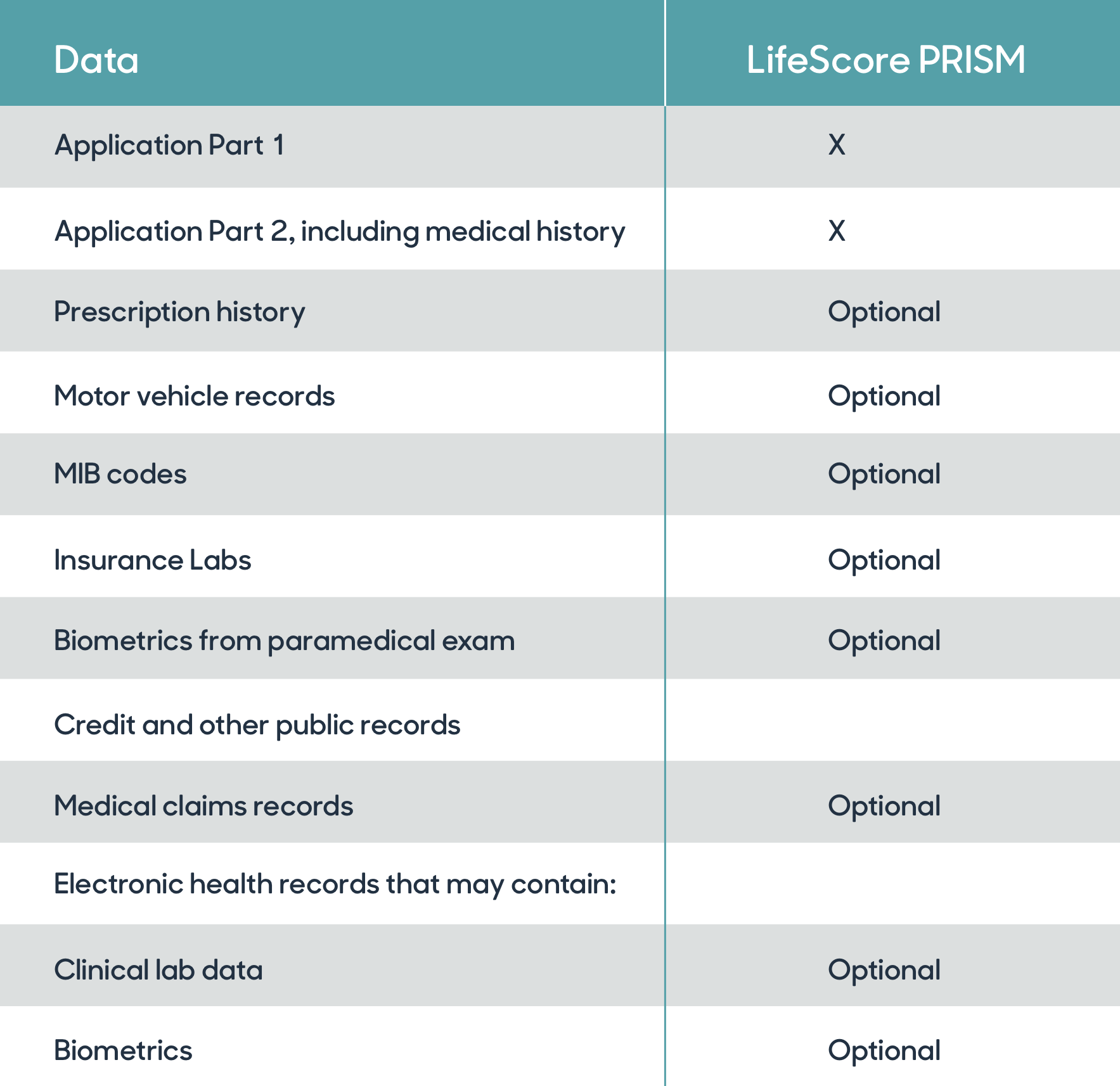
LifeScore PRISM uses medical claims codes, along with other optional data sources, to predict the presence and severity of several common medical conditions.
Another arrow in the predictive quiver
The use of MCRs to help assess risk will continue to grow. Given the complexities and challenges associated with using MCR data, carriers and reinsurers in the industry may want to partner with a vendor that has already overcome many of the challenges we discussed above. We’ve found that MCR data and the right predictive model can automate more applicants by reducing kick-outs due to common and often well-managed medical conditions and that the data has a host of other applications.
We use MCR along with data from several other sources to predict the presence and severity of specific impairments. As a result, a carrier or reinsurer can keep more applicants in an automated underwriting process, save time and resources, and deliver a better CX.
To learn more, contact us here.
1https://etactics.com/blog/medical-billing-error-statistics



